When you have an application that uploads files using input file field elements, then this is by default an all-or-nothing operation. If the user's internet connection breaks midway, they have to start the upload process from the beginning.
For downloading resources via HTTP, there is a built-in way to resume the process, as described in the HTTP/1.1 specification. When the download fails, the client can send a request with a range query and tell the server how many bytes have already been downloaded. When the server supports the range query, it can send only the missing bytes to the client: https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Range
Unfortunately, for uploading files, there is no such built-in mechanism in the HTTP specification. Fortunately, we have the File API, which is widely supported in all mainstream browsers. With this interface, we have access to the raw bytes of files from JavaScript, and we could build our own resume feature. Fortunately, we don't have to do that ourselves because there are already JavaScript libraries that do that for us.
In this blog post, I'll show you how to use Flow.js. Flow.js is a JavaScript library providing multiple simultaneous, stable, fault-tolerant, and resumable/restartable file uploads via the File API.
I integrated the library into an Ionic app (npm install @flowjs/flow.js) and upload files to a Spring Boot application.
Flow.js is a fork of the resumable.js library. According to the project page, Flow.js has been supplemented with tests and features, such as drag and drop for folders, upload speed, time-remaining estimation, separate file pause/resume, and more. But resumable.js is still actively maintained and worth having a look at if Flow.js does not work in your setup.
Flow.js splits the files into multiple pieces (chunks) and sends them one by one to the server. Before it uploads a chunk, it sends a GET request to ask the server if this specific piece has already been uploaded. The server answers with either a 200 (already uploaded) or a 404 (not uploaded) HTTP status code. When it receives the 404 status code, the library uploads the chunk; otherwise, it skips it.
It's not as perfect as the range solution because, in the worst case, the client uploads the same chunk multiple times, which is not as bad as uploading the whole file multiple times.
Client ¶
The example I wrote for this post is an Ionic application that captures the video stream from the camera and displays it on the screen. The user can take a snapshot of the current frame and upload it to the server as a JPEG file. And they can upload the whole video recording. Both times, Flow.js takes care of the upload process.
Here's a screenshot of how the application looks.
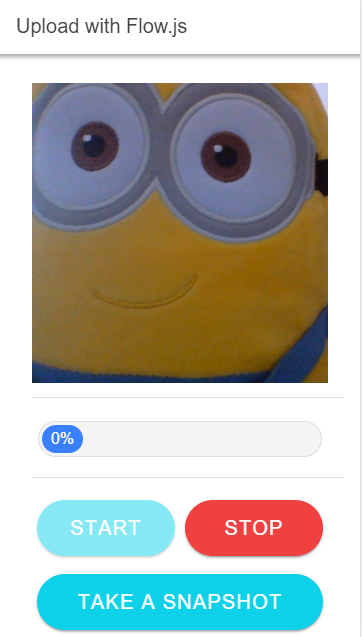
When the user clicks "Start," the application captures the video stream with the Media Capture and Streams API and streams it into a video element on the page. Additionally, it starts recording the stream with the RecordRTC (npm install recordrtc) library.
start(): void {
console.log(this.videoElement());
this.recording = true;
navigator.mediaDevices.getUserMedia({video: true, audio: false})
.then(async (stream) => {
this.videoElement().nativeElement.srcObject = stream;
await this.videoElement().nativeElement.play();
const options = {
mimeType: 'video/webm;codecs=vp9',
recorderType: RecordRTC.MediaStreamRecorder
};
this.recordRTC = RecordRTC(stream, options);
this.recordRTC.startRecording();
})
.catch(err => console.log('An error occured! ' + err));
}
Every time the user taps the "Take a Snapshot" button, the current frame of the video is internally drawn onto a canvas and then converted to a JPEG file.
takeSnapshot(): void {
const canvas = document.createElement('canvas');
canvas.width = 1280;
canvas.height = 960;
const ctx = canvas.getContext('2d');
if (ctx !== null) {
ctx.drawImage(this.videoElement().nativeElement, 0, 0, canvas.width, canvas.height);
canvas.toBlob(this.uploadSnapshot.bind(this), 'image/jpeg', 1);
}
}
The canvas.toBlob() method converts the content of the canvas element to a JPEG image. The first parameter is a callback called as soon as the conversion is finished.
The callback receives the image in a blob.
When the user taps the "Stop" button, the recording of the video is uploaded to the server.
The RecordRTC library returns a Blob of the recording, which the application passes to the uploadVideo() method.
stop(): void {
this.loadProgress = 0;
this.recording = false;
if (this.recordRTC) {
this.recordRTC.stopRecording(() => {
const recordedBlob = this.recordRTC.getBlob();
this.uploadVideo(recordedBlob);
});
}
this.videoElement().nativeElement.pause();
this.videoElement().nativeElement.srcObject = null;
}
The uploadVideo() method just wraps the blob into a File object and calls the uploadFile() method.
private uploadVideo(blob: Blob): void {
const f = new File([blob], `video_${Date.now()}.webm`, {
type: 'video/webm'
});
this.uploadFile(f);
}
The uploadFile() method is responsible for uploading the file to the server, and here we see Flow.js in action.
private uploadFile(file: File): void {
const flow = new Flow({
target: `${environment.serverURL}/upload`,
chunkSize: 50000,
forceChunkSize: true,
simultaneousUploads: 1,
permanentErrors: [415, 500, 501]
});
flow.addFile(file);
flow.upload();
The method first creates a new Flow object and sets a few configuration parameters.
target is the URL of the upload service. The handler behind this URL needs to respond to GET and POST requests. GET requests are called to test if the chunk has already been uploaded, and POST requests are used for uploading the binary data.
If you don't want to use the same URL for both services, you can specify a separate URL for the test method (testMethod).
chunkSize specifies the size of the chunks in bytes. By default, Flow.js uses a chunk size of 1MB, but the files in this example are quite small, so I set this to 50,000 bytes to see the effect of the splitting.
The forceChunkSize option specifies if all chunks have to be less than or equal to the chunkSize (true) or if the size of the last chunk can be greater than or equal to the chunkSize (false).
I had to specify the permanentErrors option because the test service returns a 404 HTTP status code, and by default, 404 is part of the permanentErrors list. If Flow.js encounters one of the listed HTTP status codes, the entire upload process is canceled.
Flow.js supports even more configuration options. You can find the complete list of all supported options on the project site: https://github.com/flowjs/flow.js#configuration
After setting up the Flow object, the method adds the file to the upload queue and starts the upload process with flow.upload().
Flow.js emits several events. In this example, I registered handlers for three of these events:
flow.on('fileSuccess', async () => {
const toast = await this.toastCtrl.create({
message: 'Upload successful',
duration: 3000,
position: 'top'
});
toast.present();
});
flow.on('fileError', async () => {
const toast = await this.toastCtrl.create({
message: 'Upload failed',
duration: 3000,
position: 'top'
});
toast.present();
});
flow.on('fileProgress', () => {
if (flow.progress()) {
this.loadProgress = Math.floor(flow.progress() * 100);
}
});
fileSuccess: Fired when the file is successfully uploaded to the server.fileError: Emitted when an error occurs.fileProgress: Fired when the progress of the file upload changes.flow.progress()returns a number between 0 and 1, indicating the current upload progress.
The progress of the file upload is visualized in a progress bar. I copied the code for this component from Josh Morony's blog post: https://www.joshmorony.com/build-a-simple-progress-bar-component-in-ionic-2/
Server ¶
For the server, we don't have a library at our disposal that joins the chunks back together. Fortunately, the implementation is not that complicated, and you can find examples in the Flow.js GitHub repository: https://github.com/flowjs/flow.js/tree/master/samples
The server for this example is a Spring Boot application with a controller and two HTTP endpoints (GET /upload and POST /upload).
The upload path, where the application stores the uploaded files, is configurable and stored in the application.properties file.
uploadDirectory: e:/upload
spring.servlet.multipart.max-file-size=50KB
spring.servlet.multipart.max-request-size=50KB
The two additional Spring configurations are essential for applications that work with HTTP uploads. The max request size is by default 10MB, and the max file size is 1 MB. The reason why there are two configuration options is that one request can transfer multiple files. Our example only uploads one file per request, and we set them to the same value. The size should be as big as the chunk size we configured in the Flow.js configuration.
@Controller
@CrossOrigin
public class UploadController {
private final Map<String, FileInfo> fileInfos = new ConcurrentHashMap<>();
private final String uploadDirectory;
public UploadController(
@Value("#{environment.uploadDirectory}") String uploadDirectory) {
this.uploadDirectory = uploadDirectory;
Path dataDir = Paths.get(uploadDirectory);
try {
Files.createDirectories(dataDir);
}
catch (IOException e) {
Application.logger.error("constructor", e);
}
}
The controller needs to know the value of the uploadDirectory property, so I inject it into the constructor with a parameter annotated with @Value.
The constructor creates the directory if it doesn't already exist.
The controller keeps track of each upload with the fileInfos map. The key is the Flow.js identifier, which is a unique string, and the value is an instance of the FileInfo class. FileInfo keeps track of the uploaded chunk numbers for each file.
@GetMapping("/upload")
public void chunkExists(HttpServletResponse response,
@RequestParam("flowChunkNumber") int flowChunkNumber,
@RequestParam("flowIdentifier") String flowIdentifier) {
FileInfo fi = this.fileInfos.get(flowIdentifier);
if (fi != null && fi.containsChunk(flowChunkNumber)) {
response.setStatus(HttpStatus.OK.value());
return;
}
response.setStatus(HttpStatus.NOT_FOUND.value());
}
The GET /upload request handler checks if a chunk with the requested number was already uploaded.
The method receives the identifier and the chunk number as request parameters and checks the fileInfo map if a mapping with the identifier and a chunk with the requested number exists. If the chunk was already uploaded, the method returns the HTTP status code 200; otherwise, it returns 404.
The second method in our controller is the POST /upload handler that receives the binary data of the chunk and stores it in a file.
@PostMapping("/upload")
public void processUpload(HttpServletResponse response,
@RequestParam("flowChunkNumber") int flowChunkNumber,
@RequestParam("flowTotalChunks") int flowTotalChunks,
@RequestParam("flowChunkSize") long flowChunkSize,
@SuppressWarnings("unused") @RequestParam("flowTotalSize") long flowTotalSize,
@RequestParam("flowIdentifier") String flowIdentifier,
@RequestParam("flowFilename") String flowFilename,
@RequestParam("file") MultipartFile file) throws IOException {
Flow.js sends a series of request parameters along with the binary data.
flowChunkNumber: Number of the current chunkflowTotalChunks: Total number of chunksflowChunkSize: Size of a chunk in bytesflowTotalSize: Total size of the fileflowIdentifier: A unique identifier for the file that Flow.js creates on the clientflowFilename: The real name of the file.
file is a MultipartFile instance that holds the binary data of the chunk.
FileInfo fileInfo = this.fileInfos.get(flowIdentifier);
if (fileInfo == null) {
fileInfo = new FileInfo();
this.fileInfos.put(flowIdentifier, fileInfo);
}
The method first checks the map if there is already an entry for this identifier.
If not, it creates a new FileInfo instance and stores it in the map.
Path identifierFile = Paths.get(this.uploadDirectory, flowIdentifier);
try (RandomAccessFile raf = new RandomAccessFile(identifierFile.toString(), "rw");
InputStream is = file.getInputStream()) {
raf.seek((flowChunkNumber - 1) * flowChunkSize);
long readed = 0;
long content_length = file.getSize();
byte[] bytes = new byte[1024 * 100];
while (readed < content_length) {
int r = is.read(bytes);
if (r < 0) {
break;
}
raf.write(bytes, 0, r);
readed += r;
}
}
Next, it creates a RandomAccessFile instance, pointing to the upload directory with the identifier as the filename, and writes the bytes from the chunk into the file at the correct position.
fileInfo.addUploadedChunk(flowChunkNumber);
if (fileInfo.isUploadFinished(flowTotalChunks)) {
Path uploadedFile = Paths.get(this.uploadDirectory, flowFilename);
Files.move(identifierFile, uploadedFile, StandardCopyOption.ATOMIC_MOVE);
this.fileInfos.remove(flowIdentifier);
}
response.setStatus(HttpStatus.OK.value());
After the write operation, the method marks the chunk number as completed by storing it in the fileInfo instance.
Then, it has to check if all parts of the file are uploaded. The fileInfo.isUploadFinished() method compares the value of flowTotalChunks with the number of uploaded chunks and returns true when all parts of the file are uploaded. When the file is completely uploaded, the application renames the file to the real file name.
You can find the complete source code for the client and server application on GitHub: https://github.com/ralscha/blog/tree/master/uploadflowjs